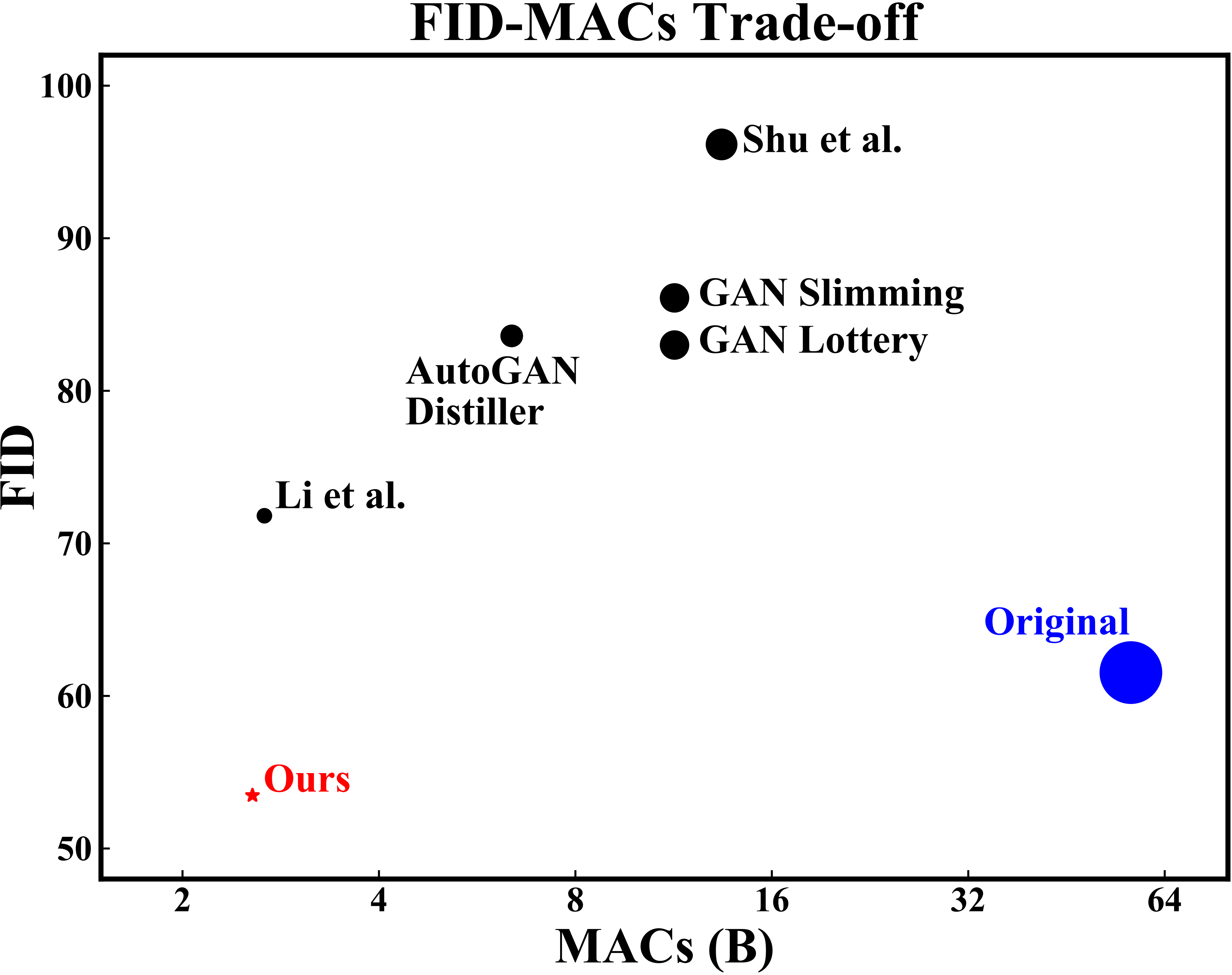
Our work is the first to compress generative models without sacrifacing the performance, and achieves the state-of-the-art (SOTA) performance-efficiency trade-off. Indeed, our compressed model can generate images with higher fidelity (lower FID) than the original huge model, with much reduced computational cost (~22×).
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process.
In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no L1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via Kernel Alignment (KA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs.
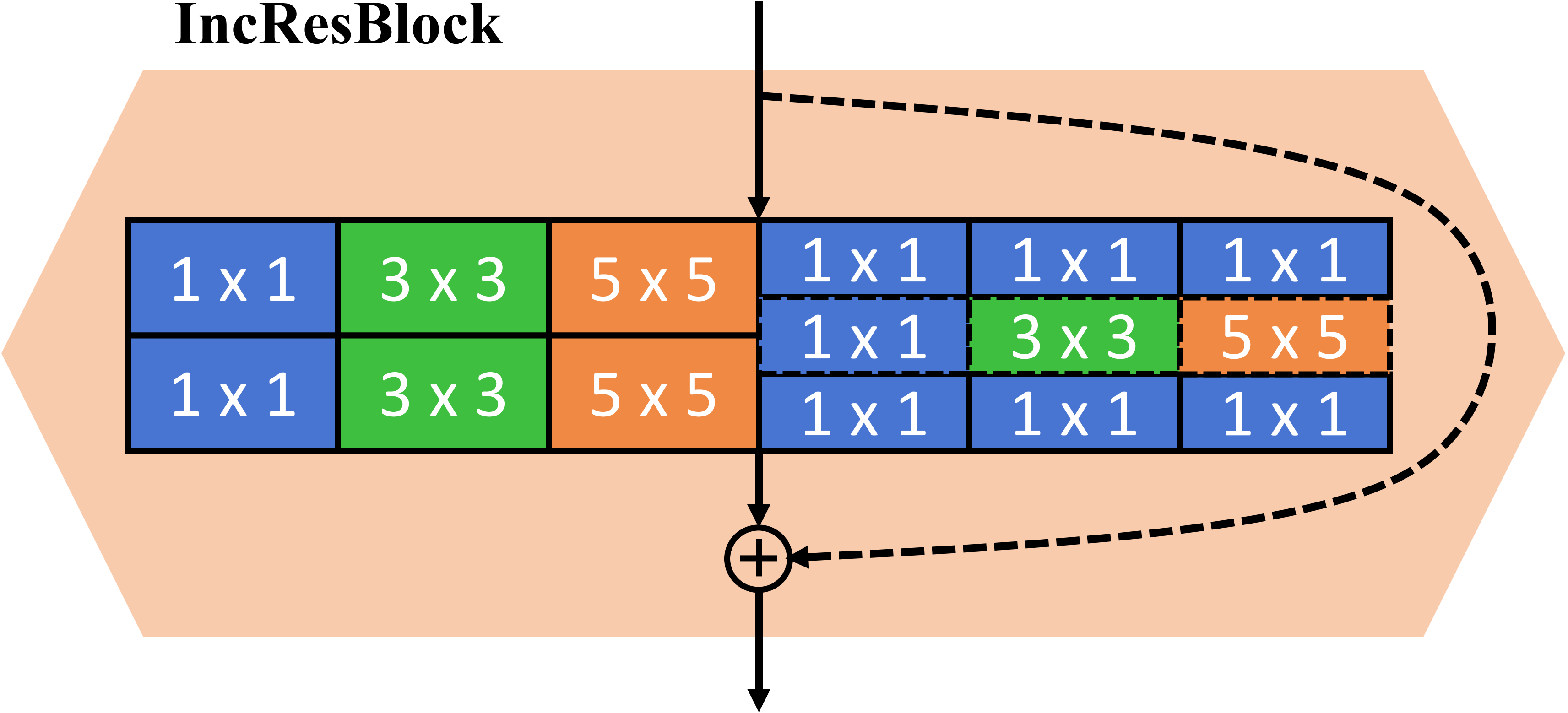
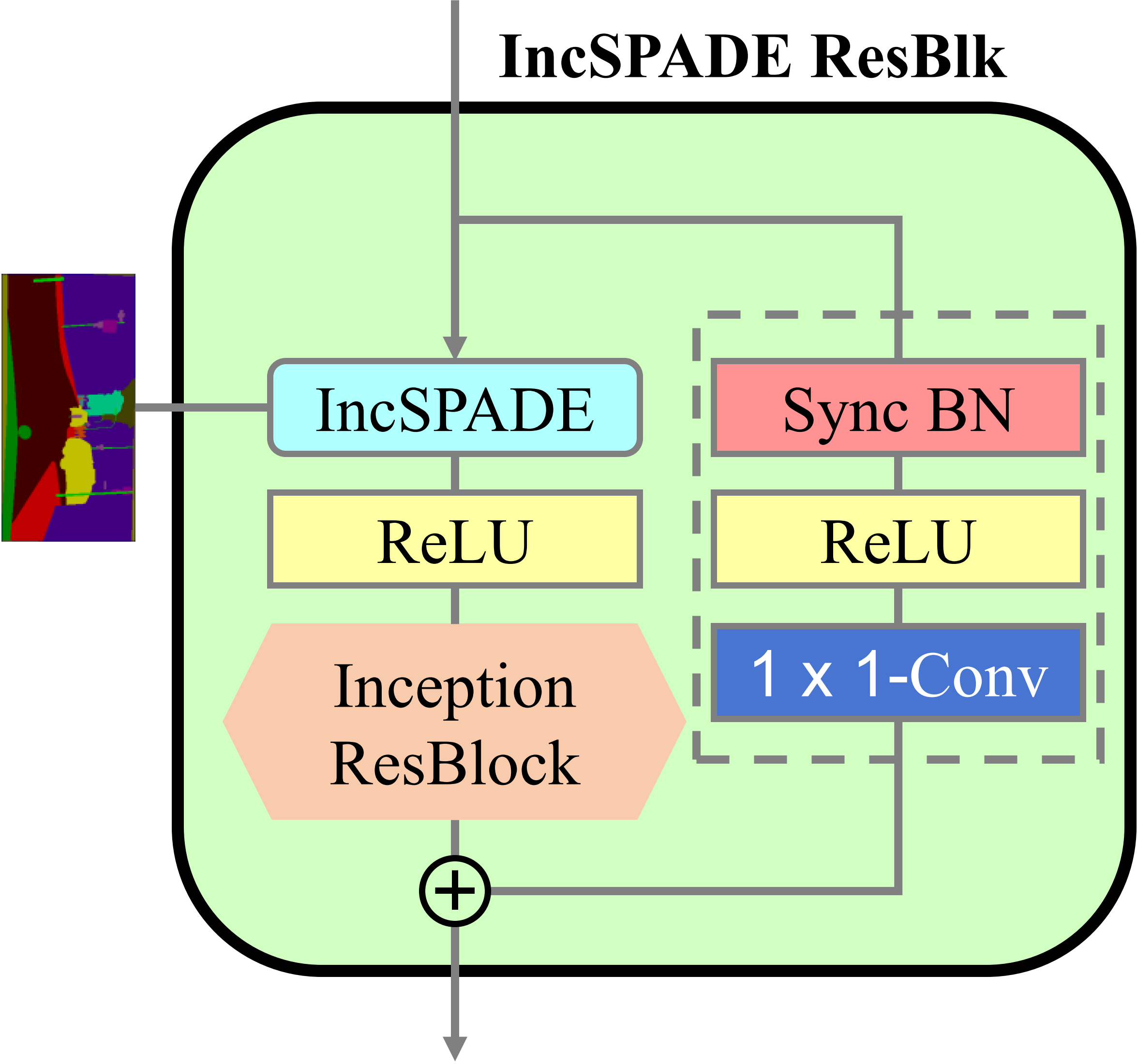
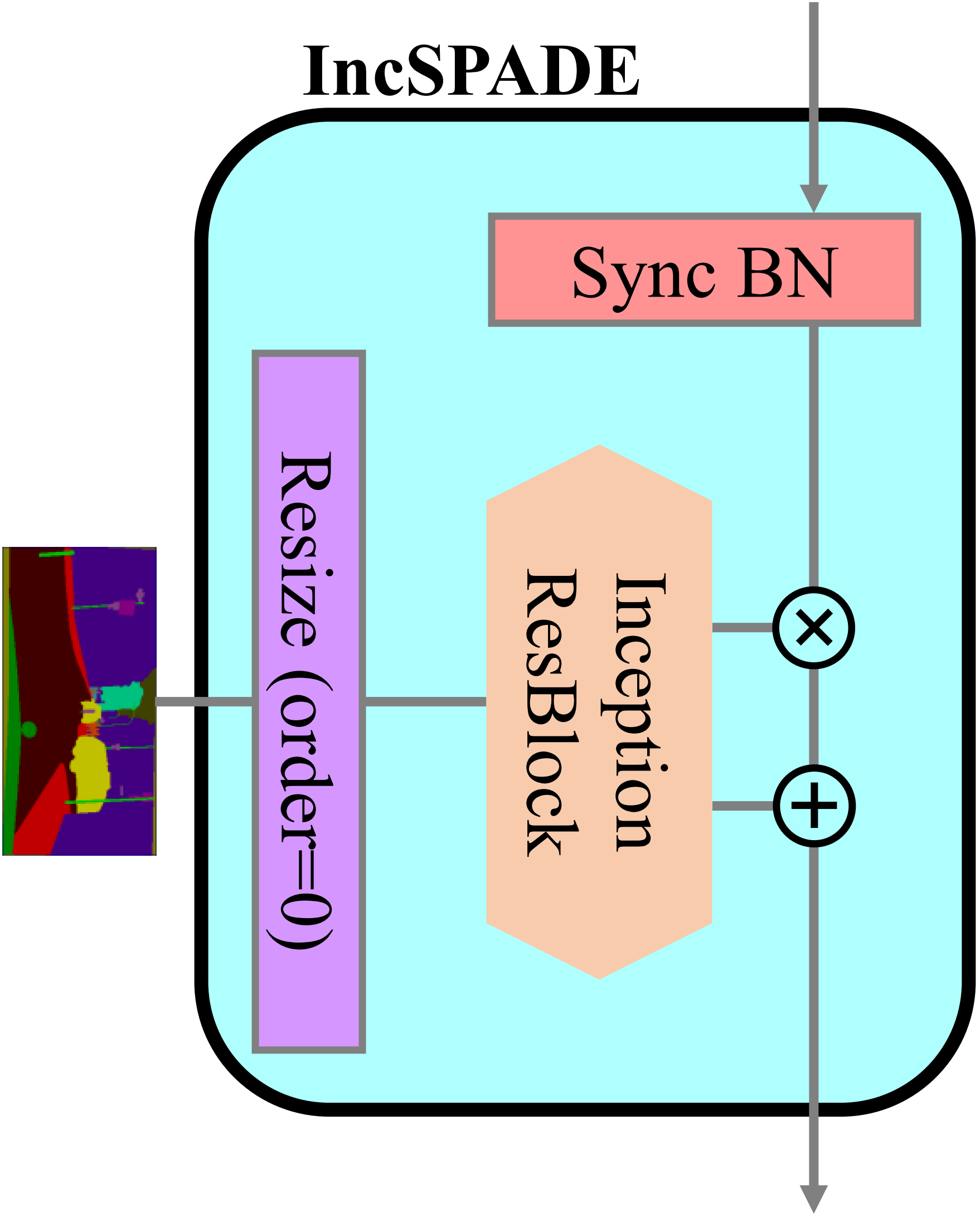
To enlarge the searching space for the generative model, we introduce inception-block and adopt both conventional and depth-wise blocks, with different kernel sizes. Also, we modify the SPADE residual block for GauGAN model, and use our inception-residual-block to replace the second layer in the main branch as well as the mapping layer inside the SPADE module. Also, to save computational cost, only the first block in the main branch remain SPADE-like.
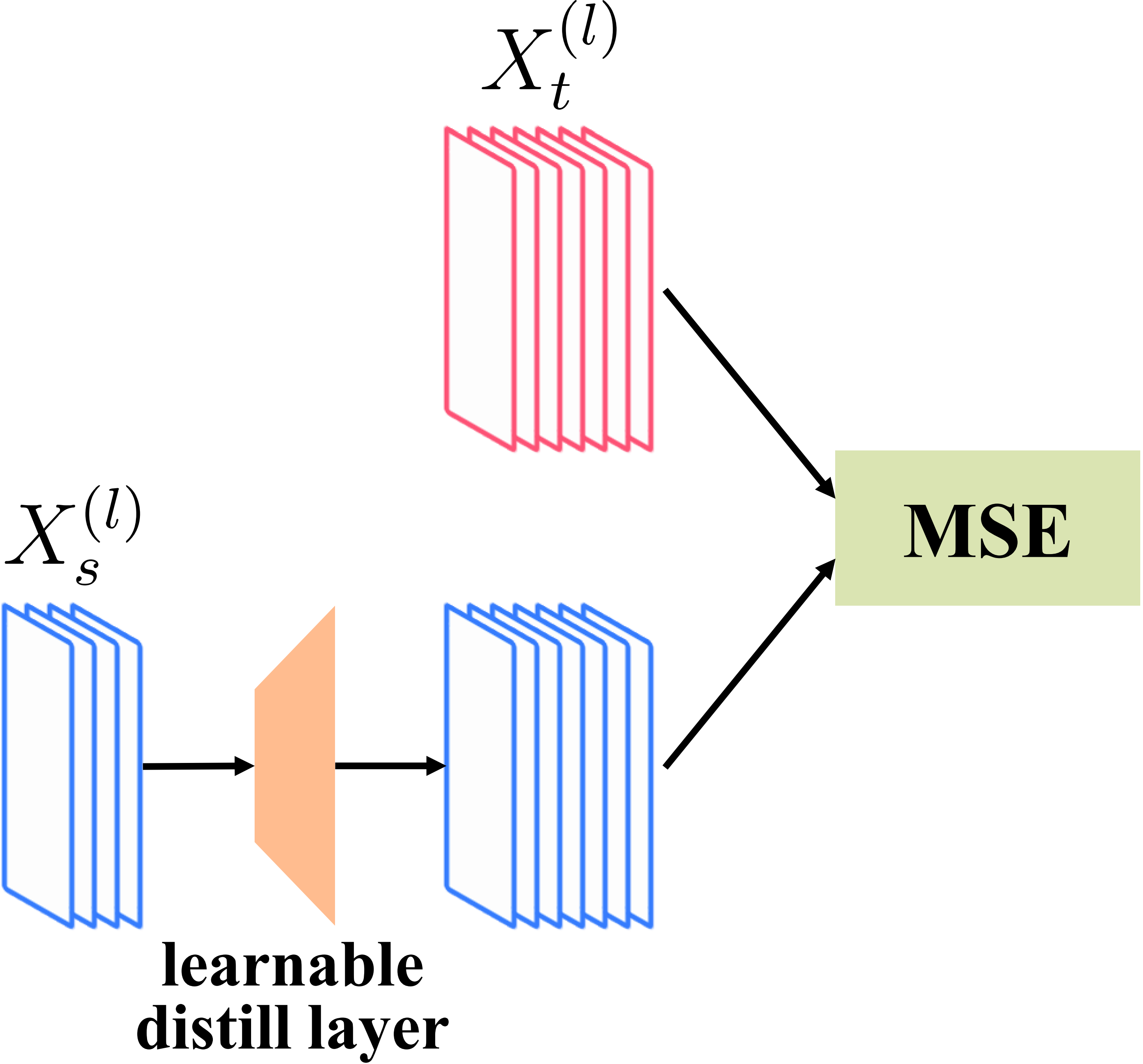
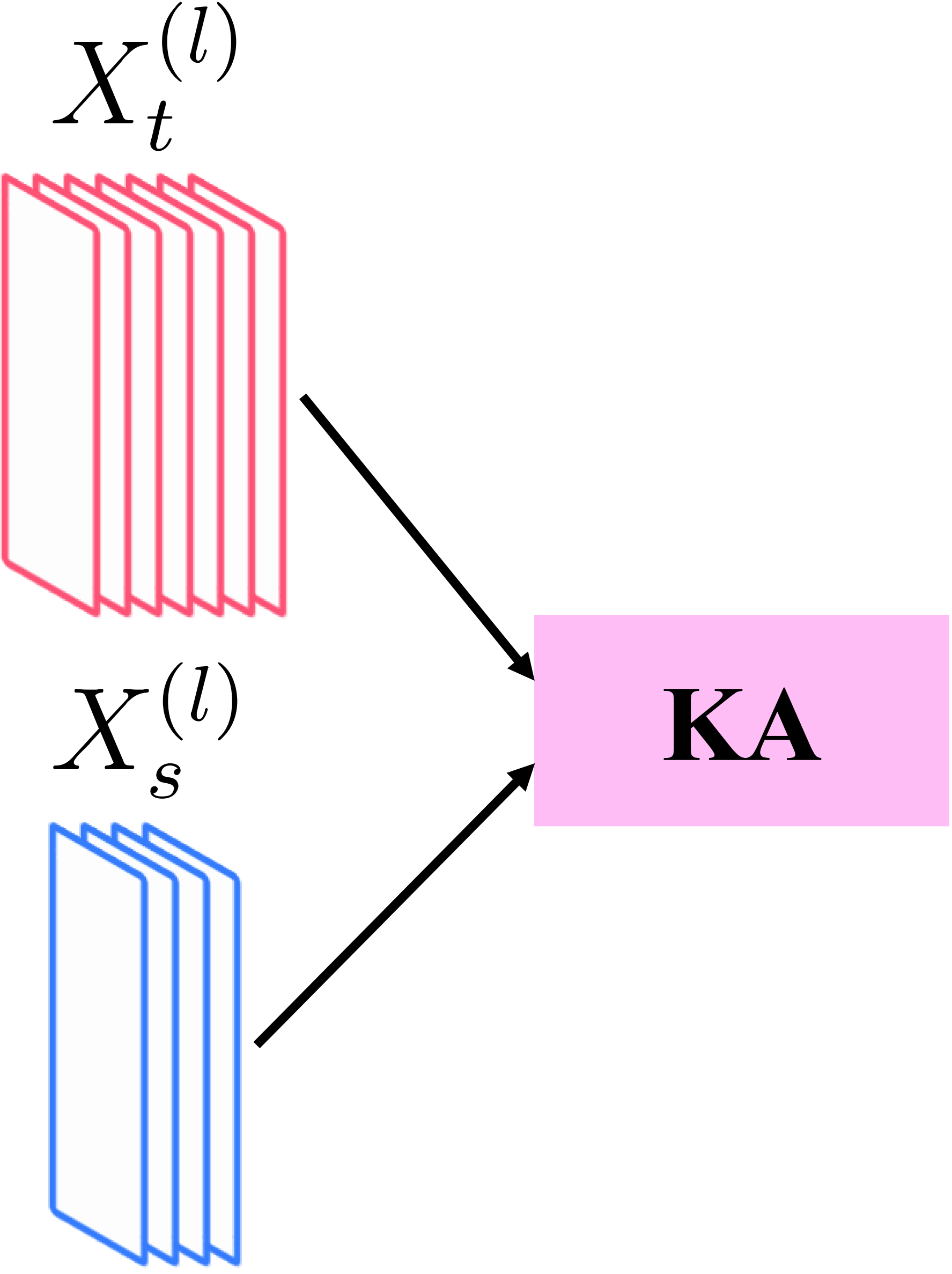
For distillation, unlike conventional method where extra learnable layers are introduced to compare features of different sizes from the teacher and student models, we propose a more direct method by maximizing the similarity between the features.
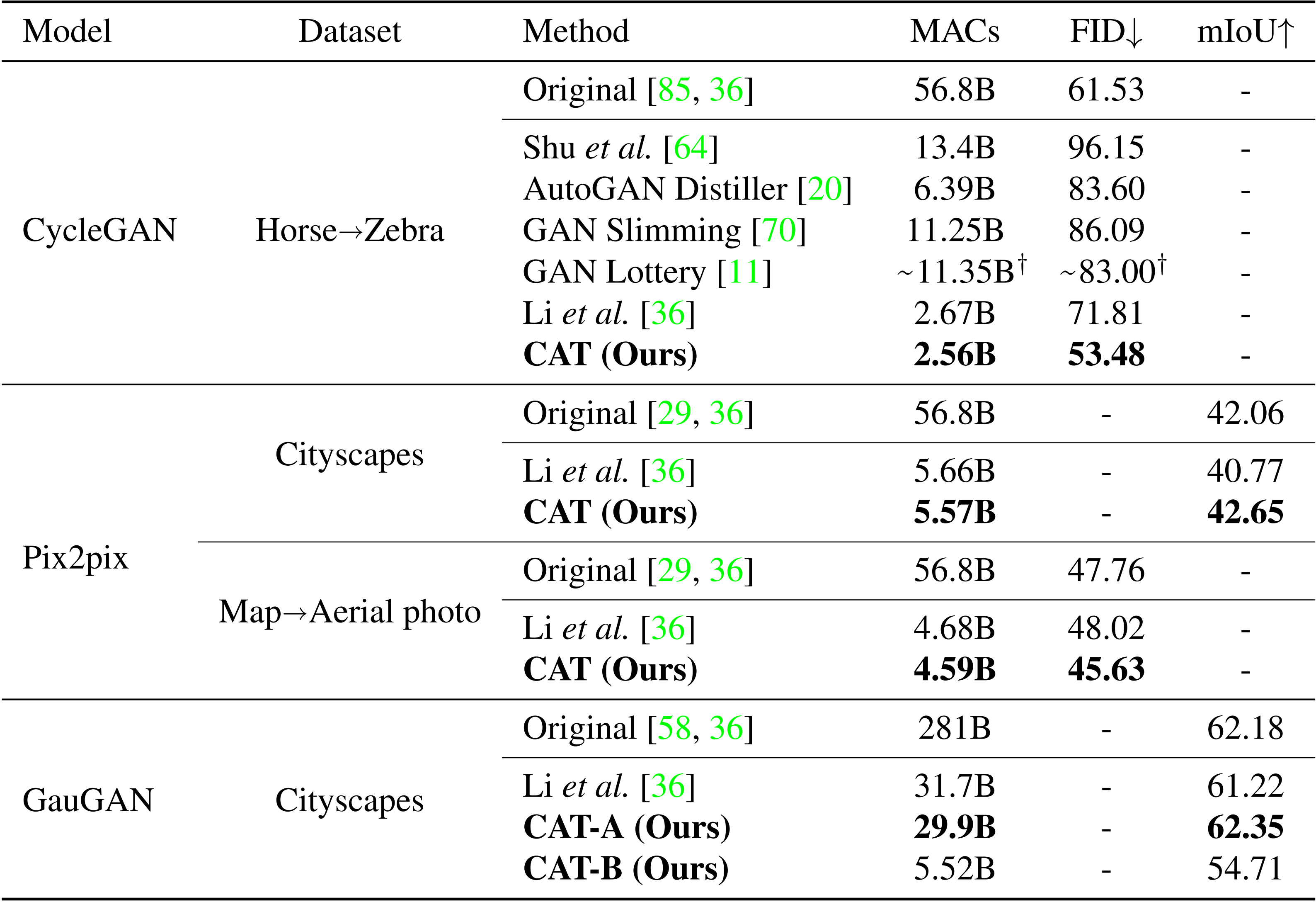
We validate our method on a wide range of models and datasets. For both simpler models such as CycleGAN or Pix2pix, and more powerful models such as GauGAN, our technique produces much smaller and more efficient architectures surpassing the original huge counterparts.
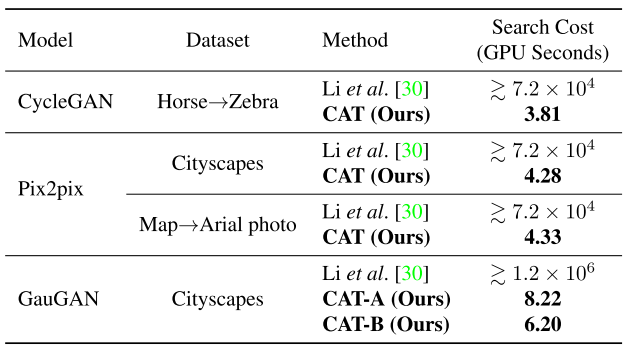
Besides better efficiency and better performance, our technique also requires much reduced searching efforts, which can be tens of thousands times smaller than existing method.

For CycleGAN model on Horse2Zebra dataset, our method compress the computational cost from 56.8B to 2.56B, which is around 22× smaller.
For Pix2pix model on Map2Aerial dataset, our method compress the computational cost from 56.8B to 4.59B, which is around 12× smaller.

For GauGAN model on Cityscapes dataset, our method compress the computational cost from 281B to 29.9B, which is around 9.4× smaller.

Note that we can compress the GauGAN model further to around 5.52B, which still gives reasonable results.
@inproceedings{jin2021cat,
title = {Teachers Do More Than Teach: Compressing Image-to-Image Models},
author = {Jin, Qing and Ren, Jian and Woodford, Oliver J and Wang, Jiazhuo and Yuan, Geng and Wang, Yanzhi and Tulyakov, Sergey},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {13600--13611},
year = {2021}
}
